
1 Introduction
At the heart of modern biodiversity science are a set of concepts and theories about species richness, stability, and function, which have been discussed since the foundational work of Elton (2001), Lindeman (1942), and MacArthur (1955) and more recently Loreau and de Mazancourt (2013). These relate to the abundance, distribution, functions, and services that biodiversity provides. Network representations of interactions among organisms are increasingly argued to be an asset to understanding and predicting the impacts of multiple, simultaneous stress on biodiversity (e.g., foundational studies on food web structure and robustness: (Cohen et al. 1990; Martinez and Dunne 1998; Dunne et al. 2002; Simmons et al. 2021)). Documenting interactions is thus one of the fundamental building blocks of community ecology and provides a powerful abstraction for mathematical and statistical modelling of biodiversity to make predictions, and to mitigate and manage threats (Windsor et al. 2023).
However, there is a growing discourse around limitations to the interpretation and applied use of networks, which have been recognised since early discussions of sampling effort and aggregation in food webs ((Cohen et al. 1990; Polis 1991; Martinez 1991); recent discussions: (Dormann 2023; Blüthgen 2010)). Against this, it is important to evaluate the value and the limitations of the various network conceptualisations and how these relate to biodiversity concepts, such as community structure or ecosystem function (Blüthgen and Staab 2024). In this perspective we aim to provide an overview of different food web representations, particularly how each representation embeds assumptions about the processes that determine interactions (Section 3) about the levels of organisation at which this occurs (i.e. the biological, ecological, spatial/temporal scales) and the way in which we construct the resulting networks (Section 4).
Network construction reflects both the data used and the theories governing species interactions. We still lack a clear explanation of the different assumptions and scale dependent processes that underpin network construction alongside extensive discussions about the challenges relating to data collection and observation (Blüthgen and Staab 2024; Brimacombe et al. 2023, 2024; Moulatlet et al. 2024; Pringle and Hutchinson 2020; Polis 1991; Saberski et al. 2024; Martinez and Dunne 1998; Pimm 1984). Such an understanding should deliver an acceleration in capacity to more effectively predict the impact of multiple stressors on biodiverse communities.
In their recent work, Gauzens et al. (2025) synthesised ecological networks based on node resolution and link type, with a focus on the data and methodologies underlying each representation. Here, we take a complementary theory-driven perspective by framing network construction as a hierarchical transition from feasibility to realisation of interactions. In the following sections, we review how nodes, edges, and interaction processes shape different network representations, highlighting how changes in assumptions alter ecological scale, node and link resolution, modelling approaches, and the relative importance of evolutionary versus ecological processes. We conclude by aligning these representations with key questions in biodiversity science in the Anthropocene.
2 Setting the Scene: The Not So Basics of Nodes and Edges
Ecological networks serve multiple uses, representing an ‘object’ from which inferences can be made. While many aspects of community structure can be analysed without networks (e.g., trait distributions or abundance patterns) networks provide a formal framework for capturing the organisation among species. The study of network structure and topology has a long history in ecology, rooted in early theory on energy flow (Lindeman 1942; Odum 1968), and later extended to questions of robustness, stability, and complexity (e.g., (Pimm 1984; May 1972; Dunne et al. 2002; Brose et al. 2006; Montoya et al. 2006)). More recent work has built on this foundation to link network structure to ecosystem functioning, persistence, and dynamical behaviour (e.g., (Schneider et al. 2016; Danet et al. 2024; Pilosof et al. 2017)). Networks are therefore commonly treated as response variables in tests of ecological theory and statistical models of the generative processes that give rise to observed structure and are widely used to compare communities across environmental gradients or through time (e.g., Hao et al. 2025; Pecuchet et al. 2020). They also provide a platform for evaluating downstream responses to perturbations, including secondary extinctions and robustness to species loss (e.g., (Dunne et al. 2002; Staniczenko et al. 2010; Keyes et al. 2024, 2021)), as well as inference about stability, ecosystem function, invasions, climate change, contaminants, and extinction cascades (e.g., (Delmas et al. 2017; Curtsdotter et al. 2019; Terry et al. 2025)). Against this backdrop of multiple research agendas, the definition of ‘edges’ and ‘nodes’, and the levels of organisation at which they are defined, take many forms (Poisot, Stouffer, et al. 2016; Moulatlet et al. 2024), each of which encode a series of assumptions within a network. Here we introduce a perspective on these baseline assumptions.
2.1 How do we define a node?
While nodes are conventionally described as representing species, in practice they may correspond to a range of taxonomic and non-taxonomic units, including sub-species, genera, or families, as well as trophic species (e.g., (Yodzis 1982; Williams and Martinez 2000)), feeding guilds (e.g., (García-Callejas et al. 2023)), or life-stage–specific subsets of species (e.g., (Clegg et al. 2018)). These choices reflect differences in the level, type, and consistency of resolution at which networks are constructed, rather than aggregation per se. Representing nodes at coarser or mixed resolutions can limit taxon-specific inference (e.g., whether species a consumes species b), bias estimates of degree distributions (particularly generality and vulnerability) and complicate downstream analyses such as extinction or invasion dynamics, where species identity and the consequences of loss may be obscured (Beckerman et al. 2006; Clegg et al. 2018). At the same time, there are clear justifications for using aggregated representations when the distribution of interactions among functional or trophic units is more informative than species-level detail, for example when analysing extinction patterns across feeding guilds (Dunhill et al. 2024). More broadly, issues of resolution, scale, and sampling have long been recognised as central to the construction and interpretation of food webs (e.g., (Martinez and Dunne 1998; Dunne 2006)).
2.2 What is captured by an edge?
Understanding edges requires distinguishing between potential and realised links - potential links reflect feasibility, whereas realised links reflect fluxes such as energy transfer. Links within food webs are thus a representation of either potential links between species Pringle (2020) or fluxes within a system e.g., energy transfer or material flow as the result of the feeding links between species (Lindeman 1942; Proulx et al. 2005). Edges can thus correspond to different ‘currencies’ (Gauzens et al. 2025). There is also a myriad of ways in which the links themselves can be specified. Links between species can be treated as present or absent (i.e., binary), may be defined as probabilities (Banville et al. 2025; Poisot, Cirtwill, et al. 2016) or by continuous functions which further quantify the strength of an interaction (Berlow et al. 2004). Link definition depends on both the ecological currency and how interactions are represented. For example, feasibility is unlikely to accommodate flux, but does align with binary or probability representations. Taking a food web that consists of links representing feasible interactions among a collection of species will be meaningless if one is interested in understanding the flow of energy through the network as the links are not environmentally/energetically constrained.
2.3 Network representations
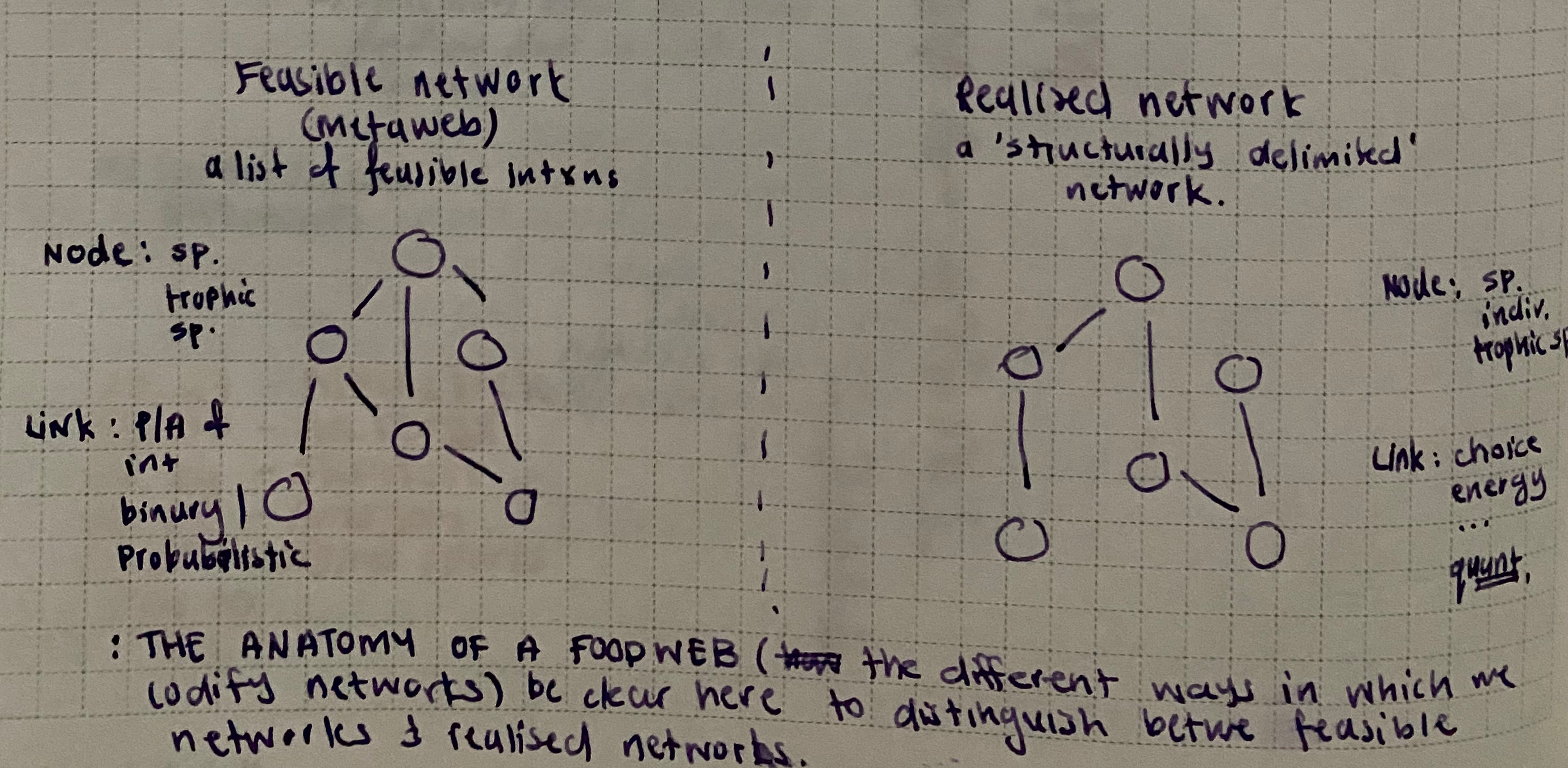
Given these definitions of nodes and edges, ecological networks can be divided into two broad types: metawebs, which represent all potential interactions within a species pool (Dunne 2006), and realised networks, which represent the subset of interactions expressed within a particular community at a given place and time. These representations differ in both the scales at which they are constructed and the processes assumed to generate their structure.
A metaweb is fundamentally a list of feasible interactions between species. Feasibility is determined by trait complementarity, typically related to feeding, and can be further constrained by species co-occurrence, producing a transition from global to regional metawebs. Metawebs therefore identify evolutionarily and regionally plausible interactions, ecologically impossible (i.e., forbidden) links (Jordano 2016b), and the potential diet breadth of species (Strydom et al. 2023).
In contrast, realised networks are localised in space and time, with links shaped by co-occurrence, environmental conditions, and diet choice. Even when represented as binary matrices, their links implicitly reflect interaction strength and energy transfer. Realised networks are therefore not simple spatial or temporal subsets of metawebs; they emerge from the processes governing whether feasible interactions are expressed. Consequently, a metaweb and realised network containing the same species may differ substantially in structure because link presence is governed by different constraints. Links absent from a metaweb represent infeasible interactions, whereas links absent from a realised network reflect context-dependent ecological constraints.
A key distinction between these representations concerns what constitutes a realised interaction. At its most general, a realised network requires more than the feasibility of species interactions; it must incorporate the ecological context that determines whether feasible interactions are expressed. This context may be represented through observation, abundance-dependent encounter rates, consumer choice, environmental conditions, or other mechanisms that constrain interaction expression. Consequently, realised networks need not be observed directly, but they should reflect processes governing the distribution or strength of interactions within a particular community. In contrast, metawebs represent the space of feasible interactions irrespective of whether those interactions are expressed locally.
3 From Nodes and Edges to Process and Constraints
In the previous section we discussed how the definition of nodes and edges, representing different scales and processes, lead to the concept of a metaweb and a realised web. The fundamental take-homes are that nodes vary in their resolution, edges vary in what kind of process they represent and the intersection of these, defined by meta- vs. realised webs, underpins distinct lines of inquiry and constraints on the type of inference we can make with networks. Here we reveal five core constraints across evolutionary and ecological scales that further delineate the transition from meta- to realised webs, exposing processes that determine the nature of links among nodes: evolutionary compatibility, co-occurrence, abundance, diet choice, and non-trophic interactions Figure 1.
3.1 Processes that determine the feasibility of an interaction
Evolutionary compatibility and co-occurrence are the two principal processes that defines the feasibility of an interaction between two species. The scale of inference and set of processes embodied in these two constraints typically combine to define a ‘list’ of interactions that are viable/feasible and defined strictly as present/absent. Reflecting on the previous section, nodes are typically species and rules defining edges are defined by trait complementarity (phylogenetic) and/or co-occurrence. Here we provide more insight into each process.
Evolutionary compatibility
This constraint is defined by shared (co)evolutionary history between consumers and resources (Segar et al. 2020; Gómez et al. 2010; Dalla Riva and Stouffer 2016; Rossberg et al. 2006) which is manifested as ‘trait complementarity’ between two species (Benadi et al. 2022). In this body of theory, the consumer has the ‘correct’ set of traits that allow it to acquire and consume the resource. Interactions that are not compatible are defined as forbidden links (Jordano 2016b); i.e., they are not physically possible and will always be absent within a network.
Networks do not properly arise from models based on this constraint. Instead, interacting species pairs are defined and these are represented as binary (possible vs forbidden) or probabilistic (Banville et al. 2025). For example, in the metaweb constructed by Strydom et al. (2022) probabilities are quantified as the confidence of a specific interaction being possible between two species. A network constructed based on evolutionary compatibility is conceptually aligned with a ‘global metaweb’, and gives us information as to the global feasibility of links between species pairs despite the fact that they do not co-occur (see Figure 1).
(Co)occurrence
The co-occurrence of species in both time and space is a fundamental requirement for an interaction between two species to occur (at least in terms of feeding links). Although co-occurrence data alone is insufficient for building an accurate and ecologically meaningful representation of feeding links (Blanchet et al. 2020), it is still a critical process that determines the possible realisation of a feeding. Knowledge on the co-occurrence of species allows us to spatially constrain a global metaweb to reflect regional metawebs (Dansereau, Barros, et al. 2024). In the context of Figure 1 this would be the metawebs for regions one and two.
We reinforce that these two constraints don’t deliver a network per se, but a list of feasible species pairs. Although it is possible to build a network from the list of interactions generated by these constraints, it is important to be aware that the structure of this network is not constrained by any community context - just because species are able to interact does not mean that they will (Poisot et al. 2015; Caron et al. 2024).
3.2 Processes that realise networks
In contrast to the above, here we highlight three processes that influence the realisation of an interaction between species and thus form the conceptual basis for realised networks. As we show in Figure 1, a ‘truly realised’ network is the product of properties of the community (abundance and non-trophic interactions) and the individual (diet choice). This represents a conceptual shift from considering the feasibility for species pairwise interactions to considering the edge as a representation of energy flow. Such a transition requires information about how the community, the environment and the individual constrains network topology as defined by consumer choice (Quintero et al. (2024), Section 2.3)
Abundance
Abundance as a realising process emerges from a null model for energy acquisition: organisms feeding randomly will consume resources in proportion to their abundance (Stephens and Krebs 1986). Here, abundance of different prey species influences the distribution of links in a network (Vázquez et al. 2009) by defining a preference linked to individuals among species meeting (Poisot et al. 2015; Banville et al. 2025). Abundance data (linked to a derived metaweb) delivers a foundation ruleset that can define the distribution and strength of links. Of note, however, is that such abundance constrained interactions are not necessarily contingent on there being any compatibility between species (Canard et al. 2012; Momal et al. 2020; Pomeranz et al. 2019).
Diet choice
It is well established that consumers make more active decisions than eating items in proportion to their abundance (Stephens and Krebs 1986). Ultimately, consumer choice is underpinned by an energetic cost-benefit framework centred around profitability and defined by traits associated with acquisition and consumption of a resource (Wootton et al. 2023; Smith et al. 2021). Energetic constraints are invoked to construct networks in a myriad of ways (e.g., Beckerman et al. 2006; Pawar et al. 2012; Portalier et al. 2019; Cherif et al. 2024).
Unlike metaweb approaches, these models generate realised webs as emergent outcomes of consumer behaviour. We also here make a distinction, developed below, with models like the Niche Model (Williams and Martinez 2000), where diet choice is implicit in its probabilistic network generating function, but it is working to replicate the expected structure of the network, and this structure does not emerge from node-based rules. Note that we select diet choice as a term to capture rules linked to optimal foraging (Pyke 1984) and metabolic theory (Brown et al. 2004) for capturing the energetic constraints on the distribution and strength of interactions.
Non-trophic interactions
We include non-trophic interactions (see Miele et al. 2019) here not as a determinant of links, but a modifier of them - they are the community context above and beyond co-occurrence and abundance. Non-trophic interactions include competition for space, predator interference, refuge provisioning, recruitment facilitation as well as non-trophic effects that increase or decrease mortality. These interactions specifically modify either the realisation or strength of trophic interactions (Ings et al. 2009; Golubski and Abrams 2011; Pilosof et al. 2017; Staniczenko et al. 2010; Kamaru et al. 2024) and represent direct (e.g., predator \(a\) outcompetes predator \(b\)) and indirect (e.g., mutualistic/facilitative interactions) mechanisms.
Some interactions, such as pollination, occupy an intermediate position in this framework, as they combine trophic components (e.g., resource consumption) with non-trophic effects that influence reproduction, recruitment, and population persistence (Holland et al. 2002; Bascompte and Jordano 2007; Sauve et al. 2016). They operate on the realisation of a network by altering the fine-scale distribution and abundance of species and relative contributions of direct and indirect effects to biomass, persistence, stability, and the functioning of the communities (Kéfi et al. 2012, 2015; Buche et al. 2024; Miele et al. 2019).
4 Network construction
The above five processes are central to understanding the assumptions inherent in building different types of networks. Each of the processes, or combinations thereof, deliver a unique set of boundary conditions on what a network represents and can be used for. Here we build on the introduction of these five processes to further categorise the approaches to constructing networks. The utility of a network depends on the processes used to construct it. Different construction approaches encode different assumptions about how interactions arise, and therefore support different ecological questions.
4.1 Why construct networks?
Networks are a representation of biodiversity. In a perfect world, we might know about all interactions. However, the empirical collection of interaction data is both costly and challenging to execute (Jordano 2016a, 2016b; Poisot et al. 2021). In the absence of robust empirical data, we use ‘models’ that facilitate interpolation and gap-filling of existing empirical datasets (e.g., Biton et al. 2024; Stock et al. 2017; Dallas et al. 2017; Poisot et al. 2023), predict the feasibility of interaction among pairs of species, or directly predict network structure (see Strydom et al. 2021 for a broader discussion).
Networks are unique in delivering more than just estimates of species richness. As noted in the introduction, a network embodies the organising structure of biodiversity and allows numerous opportunities for ‘downstream’ analysis, including the comparison of structures, estimation of energy flux or extinction dynamics and ultimately form the structural inputs to dynamical systems models that facilitate ecological and conservation relevant inference about productivity-diversity-stability-function relationships (Danet et al. 2024) in space and time. But making such inferences requires careful attention to one or more of the processes discussed in Section 3. While these network representations may be simplifications of the truth (Stouffer 2019), they remain critically useful tools as they allow us to move beyond simple descriptions of species richness to test hypotheses about community architecture and ecosystem functioning that would be otherwise impossible to assess.
4.2 Construction through induction
Constructing feasible or realised networks can be framed as an ‘inductive reasoning’ process where insight and generalisation arise from a set of observations and relationships around feeding. Inductive reasoning as a foundation for network construction is implemented at node and network levels.
4.2.1 Species specific induction
When applied at the node level, species-specific networks are created based on expected feeding interactions. When applied at the network level, networks are judged by their structural properties. All methods in this inference space rest on a set of three assumptions: there are a set of ‘feeding rules’ that underpin interaction feasibility (Morales-Castilla et al. 2015); these rules are phylogenetically conserved (Dalla Riva and Stouffer 2016; Bramon Mora et al. 2018); and they can be specified by matching the traits between consumer and resource.
Evolutionary compatibility and co-occurrence constraints have been critical to the construction of ‘first draft’ networks for communities for which we have no interaction data (Strydom et al. 2022). They are also central to interpolation in data poor regions and predicting interactions for ‘unobservable’ communities e.g., prehistoric networks (Yeakel et al. 2014; Fricke et al. 2022; Dunhill et al. 2024) or future, novel community assemblages (Van der Putten et al. 2010). Furthermore, they have the capacity to evaluate a role of interactions among species relative to their distribution by accounting for the role of the environment and the role of species interactions (Higino et al. 2023; Pollock et al. 2014; Gravel et al. 2019; Albouy et al. 2014).
Feeding rules can be specified in several ways. Expert-based approaches define feasible interactions using trait matching (Shaw et al. 2024; Roopnarine 2017), while mechanistic approaches often rely on trait-based relationships between consumers and resources (Gravel et al. 2013; Rohr et al. 2010). Alternatively, statistical and machine-learning methods infer interaction probabilities from observed networks using ecological predictors such as traits and phylogeny (Pichler et al. 2020).
Rules are also defined by correlating real world interaction data with suitable ecological proxies for which data is more widely available (e.g., traits) using some sort of binary classifier (see Pichler et al. (2020) for an overview). These include generalised linear models (e.g., Caron et al. 2022), random forest (e.g., Llewelyn et al. 2023), trait-based k-NN (e.g., Desjardins-Proulx et al. 2017), and Bayesian models (e.g., Eklöf et al. 2013; Cirtwill et al. 2019).
Finally, graph embedding uses the structural features of a known network to infer the position of species in an unknown network through the decomposition of the interaction onto the embedding space (see Strydom et al. (2023)). This decomposition relies on a combination of ecological proxies (e.g., phylogenetic relatedness Strydom et al. (2022)) in conjunction with known interactions to infer the latent values of species, which can then be mapped onto decomposition of a known network.
4.2.2 Structure-based induction
These models generate ecologically realistic network structures using simple probabilistic rules. They are commonly used as null expectations, for comparative analyses, and as inputs to dynamical models. The determination of links between species is not directly linked to properties of the nodes. This means these networks are usually not species specific. Although they require little empirical information, they encode explicit assumptions about expected network structure.
Stochastic network models use a probabilistic ruleset about diet choice and niche breadth to reflect fundamental ideas of foraging biology. These models that are based on the compartmentalisation and acquisition of energy for species at different trophic levels (Allesina and Pascual 2009; Krause et al. 2003) and that network structure can be determined by distributing interactions along single dimension (the ‘niche axis’; Allesina et al. (2008)). Typically, these models parametrise some aspect of the network structure (although see Allesina and Pascual (2009) for a parameter-free model). These models include the most used network generator, the Niche model (Williams and Martinez 2000), as well as the original Cascade model (Cohen et al. 1990) and the derived Nested hierarchy model (Cattin et al. 2004). Even though these networks are derived without any real-world data they are still able to recover the structure of empirical networks (Stouffer et al. 2005). These models often form the basis for dynamic models e.g., the allometric trophic network (Brose et al. 2006; Schneider et al. 2016) and bioenergetic food web models (Delmas et al. 2017).
4.3 Construction through deduction
In contrast to metaweb construction, realised networks require assumptions about the ecological processes that determine whether feasible interactions are expressed. These approaches are deductive because interactions emerge from explicit assumptions about encounters, foraging behaviour, energetic constraints, or interaction modification. These approaches operationalise the abundance, diet-choice, and non-trophic processes introduced in Section 3.1. The resulting networks are widely used to study energy flux, extinction dynamics, and ecosystem functioning. They also provide the structural backbone for dynamical systems modelling to address questions about stability-structure-productivity-function relationships, secondary extinction dynamics, species invasion and climate change. There are two broad groups of models in this deductive category.
These models capture the behaviour of the nodes by explicitly considering the properties of the different species in the community. Which means that there is a degree of variance in which links are predicted between species unlike the more ‘static’ predictions made by inductive models. However, these networks are costly to construct in real world settings (requiring data about the entire community, as it is the behaviour of the system that determines the behaviour of the part) and also lack the larger diet niche context afforded by metawebs.
4.3.1 Abundance-based models
Neutral networks are built on the assumption that foraging decisions are tied only to the abundance of species within the community (Canard et al. 2014; Krishna et al. 2008). Here links are solely determined by the relative abundance of the different species in the community. Although unrealistic as a complete explanation, neutral models can be combined with inductive approaches to generate more localised predictions (Pomeranz et al. 2019).
4.3.2 Energetics-constrained models
There is a broader group of models that focus on determining interactions in terms of energetic constraints on diet breadth, often using the ratio of consumer-resource body size as a proxy for capturing the energetic constraints of feeding. Models such as those developed by Portalier et al. (2019) and Wootton et al. (2023) are similar to the mechanistic approaches discussed in Section 4.2, however instead of determining interactions based on mechanistic feasibility it is rather constrained by the energetic cost of predation. Note that although these models do not place any explicit constraints on the expected structure of the network, the links should still be considered as ‘realised’ owing to the energetic constraint placed on links. A different subset of diet models (e.g., Beckerman et al. 2006; Petchey et al. 2008) use a diet choice approach, however like the stochastic network models they also embed assumptions on network structure. Thus, these models predict both interactions and network structure simultaneously, although they would benefit in being refined by more explicitly accounting for trait-based (i.e., feasibility) parameterisation (Curtsdotter et al. 2019).
5 Making Progress with Networks
The motivation to leverage network ecology in conservation ecology, environmental risk assessment and natural resource management stems from a shift away from species/population specific measures of the effects of stress and disturbance to community level metrics of these impacts. These metrics, such as resilience and more generally stability, ecosystem function and biodiversity, are natural properties of networks. This suggests that modern conservation, risk assessment and resource management requires robust network tools to support decision making.
This is also true in the disciplines of ecology and environmental science and their focus on abundance, distribution, functions and services that biodiversity provides (Loreau and de Mazancourt 2013). Major questions remain, for example, about stability-diversity-productivity relationships, the impacts of extinctions and invasions, and the impacts of multiple stressors operating at multiple ecological scales. A network approach to answering these types of questions specifically allows us to evaluate how environmental gradients and anthropogenic stress map through direct and indirect effects among species in a complex community and reveal fundamental patterns and understanding of processes in the natural world.
To effectively use networks to aid us in answering questions about conservation/risk assessment/management and core ecological theory, we need to be mindful that we are mapping the correct network representation to the question of interest (Gauzens et al. 2025). Notably, there are certain questions that cannot be answered using specific network representations as the scale of the question of interest is fundamentally misaligned with the process captured by a specific network representation (Section 3.1), the underlying data that is used to construct it (Section 4), or both.
Here we discuss and map the different network representations shown in Figure 1 to ‘appropriate’ research questions and agendas (see also Table 1). We also highlight some of the key methodological challenges that currently limit our conceptualisation of a ‘network’ and thus impact their effective practical application in real world settings.
| Network Representation | Example Research Question | Representative Studies |
|---|---|---|
| Global Metaweb | How will novel communities respond to e.g., extinction, turnover, invasion and rewilding \(^\checkmark\) | Gravel, Albouy, et al. (2016); Dunne et al. (2002) |
| Diet-based conservation focusing not only on the target species but the species it might depend on for food resources \(^\Delta\) | Rooney and McCann (2012); Curtsdotter et al. (2011); McDonald-Madden et al. (2016) | |
| Rewiring capacity/potential of species by looking at the entire diets of species \(^\Delta\) | Gilljam et al. (2015); Staniczenko et al. (2010); Su et al. (2024); Marjakangas et al. (2025) | |
| Eco-Evolutionary dynamics and how they relate to the conservation and origination of feeding strategies \(^\times\) | Poisot et al. (2015); Baskerville et al. (2011) | |
| Regional Metawebs | Applied use potential of questions highlighted for global metawebs at the management scale e.g., a protected area \(^\Delta\) | Albouy et al. (2014); Pellissier et al. (2018); Estrada and Bodin (2008) |
| Refinement/extension of species distribution models by incorporating co-occurrence and species associations e.g., predator and prey \(^\checkmark\) | Araújo and Luoto (2007); Kissling et al. (2012) | |
| Realised Webs | The allocation of multiple stressors across networks \(^\Delta\) | Crain et al. (2008); Beauchesne et al. (2021) |
| Temperature threshold to community collapse \(^\Delta\) | O’Gorman et al. (2019); Petchey et al. (2010) | |
| Extinction and persistence after harvesting/invasion/extinction \(^\checkmark\) | Allesina and Tang (2012); Yodzis (2001) | |
| Stability-diversity-productivity-function \(^\checkmark\) | Thébault and Fontaine (2010); Rooney and McCann (2012) | |
| Explicilty tying ecosystem level processes and nutrient flows to networks \(^\times\) | Moore et al. (2004) | |
| Meta communities and the idea of meta-network-communities \(^\Delta\) | Gravel, Massol, et al. (2016); Gilarranz et al. (2017) |
5.1 Key Eco-Evo-Conservation Questions
5.1.1 Global Metawebs
Global metawebs are most appropriate for questions centred on interaction feasibility and potential diet breadth. They provide a platform for exploring hypothetical or novel communities under climate change (Hui and Richardson 2019), species invasions, reintroductions, and rewilding, and the potential rewiring capacity (Marjakangas et al. 2025). Because they focus on feasible rather than realised interactions, global metawebs are also well suited to studying eco-evolutionary dynamics and how evolutionary history, natural selection, and phenotypic plasticity shape interaction niches.
5.1.2 Regional Metawebs
Regional metawebs extend these questions by explicitly incorporating species co-occurrence and therefore provide a more management-relevant perspective. They can be used to refine species distribution models and projections of future community composition (García-Callejas et al. 2023; Hao et al. 2025). However, caution is required when comparing regional metaweb structure across space or environmental gradients, as observed differences may reflect species turnover (e.g., \(\beta\)-diversity) rather than changes in interaction processes.
5.1.3 Realised networks
Realised networks are best suited to questions concerning how community and environmental context shape interaction structure and ecosystem functioning (Thuiller et al. 2024). They provide the appropriate framework for studying stability, resilience, biodiversity dynamics, ecosystem functioning, extinction cascades, invasions, climate change impacts, and network rewiring through time. By capturing interactions that are actually occuring, realised networks allow investigation of how perturbations propagate through communities and influence persistence.
The increasing availability of long-term interaction datasets is expanding opportunities to address these questions (Danet et al. 2024; Wooster et al. 2024). However, empirical datasets often accumulate interactions across extended periods, potentially obscuring temporal variation in realised interactions (Polis 1991). Developing approaches that better reconcile empirical networks with realised community dynamics therefore remains an important challenge.
5.2 Key methodological challenges
As noted above, the three network types highlight longstanding methodological challenges that limit both the precision and accuracy of ecological inference. Here we briefly review these challenges and emerging opportunities to address them.
Understanding what empirical data represents: Robust inference requires understanding what constitutes an observed interaction, whether recorded directly (predation events) or indirectly (e.g., gut contents or stable isotopes). Because empirical networks often accumulate observations across space and time, they may be conceptually closer to metawebs than realised networks.
The validation of network structure: Considerable progress has been made in assessing how well models recover pairwise interactions (Strydom et al. 2021; Poisot 2023), yet there remains no clear framework for evaluating their ability to recover network structure (Allesina et al. 2008; Tylianakis et al. 2010). This raises two related questions: what constitutes an appropriate benchmark, and which aspects of network recovery matter most? For metawebs, accurately identifying both present and forbidden links may be essential, whereas for realised webs it remains unclear whether recovering pairwise interactions, aggregate properties (e.g., connectance), or both should be the primary objective.
Transitioning between metawebs and realised webs: Most approaches for modelling realised networks do not explicitly incorporate evolutionary constraints (although see Van De Walle et al. (2023); Wootton et al. (2023)). Progress will likely require either ensemble approaches (Becker et al. 2022; Terry and Lewis 2020) or methods for downscaling metawebs into realised networks (e.g., Roopnarine 2006). However, any such transition must retain clarity about the meaning of links - structurally realistic networks do not necessarily represent realised prey choice or energy flow.
Developing frameworks that allow transitioning between metawebs and realised representations will also facilitate integration with metacommunity, metaecosystem, and ecosystem-level theory (Massol et al. 2011; Liu et al. 2025). Doing so requires clear definitions of what constitutes a network and where its spatial and temporal boundaries lie (Fortin et al. 2021).
Making networks more tractable in applied spaces: The application of networks to conservation and management remains limited by difficulties in defining network boundaries, aligning them with management units, and interpreting network metrics in policy-relevant ways (Dansereau, Braga, et al. 2024). Addressing these challenges will require stronger links between network structure and ecosystem function, alongside careful matching of analytical tools and network representations to management objectives (O’Connor et al. 2025; Pellissier et al. 2018).
Taken together, these challenges highlight three overarching messages. (i) Network representations are inseparable from the data and assumptions used to construct them; (ii) validation and benchmarking must be aligned with the intended network type and research question; and (iii) greater conceptual clarity is needed when transitioning between metawebs and realised networks, particularly in applied contexts. Explicitly articulating these distinctions is essential if networks are to be used rigorously and transparently across scales.
6 Concluding Remarks
Network representations encode different processes: Different network representations capture distinct assumptions, data structures, and ecological processes; understanding the interplay between a network’s structure and the processes it encodes is critical for determining which questions it can address.
Network representations are not interchangeable: There is no universally optimal network representation. The utility of a network depends entirely on how well its underlying assumptions and data align with the intended scale and process of analysis.
Explicit assumptions are essential for evaluation: Explicitly articulating the assumptions behind network assembly facilitates a more critical evaluation of network suitability and inferential power. It is important that we move beyond the uncritical and default reliance on conventional network representations in favour of understanding the consequences of selecting a specific representation or reconstruction/modelling approach.
A unified framework improves application and progress: The framework presented here provides a structured basis for comparing network representations and evaluating their suitability across conceptual, methodological, and applied contexts. Establishing this standard is essential for preventing the misinterpretation of network data and for addressing foundational questions in biodiversity science.